
Blog
kz43x9nnjm65 Explained: Meaning, Use, and Real Impact

At first glance, kz43x9nnjm65 looks like a random string, yet it carries more meaning than most people expect. In many digital systems, identifiers like this quietly shape how data moves, connects, and stays secure. This article explores kz43x9nnjm65 from a practical, experience-based angle, not theory alone. By the end, you will understand why such identifiers exist, how they are used, and what makes them surprisingly important in everyday technology.
Understanding the Nature of Digital Identifiers
Digital identifiers exist to give structure to systems that would otherwise be chaotic. When platforms manage millions of entries, they need labels that never collide or repeat. These labels often look meaningless to humans, but they act like fingerprints for machines. Their value comes from consistency, not readability, which is why they often appear random and complex.
From working with databases and platforms, it becomes clear that identifiers reduce errors. Names change, titles shift, and descriptions evolve, but a stable identifier remains constant. This stability allows systems to track history, permissions, and relationships over time. Without it, even small updates could break links or corrupt records.
Another reason identifiers matter is speed. Systems process numeric or alphanumeric strings faster than descriptive text. That efficiency becomes critical at scale. When millions of operations happen per second, even small optimizations matter. Identifiers quietly support this efficiency without demanding attention from end users.
Will You Check This Article: jyokyo Explained: Meaning, Context, and Practical Use
Why Randomized Strings Are Preferred Over Names
Human-readable names feel intuitive, but they are risky in large systems. Two people can share a name, and one name can change over time. Randomized strings avoid ambiguity entirely. Each one is unique by design, which removes guesswork and reduces conflicts across systems that interact with each other.
In real projects, name-based systems often fail during growth. As data expands, exceptions multiply, and workarounds pile up. Random strings prevent this creep. They scale cleanly because uniqueness is mathematically enforced rather than socially assumed. This makes them ideal for global platforms with diverse users.
There is also a security angle. Predictable names are easier to guess. Randomized identifiers make unauthorized access harder because patterns are not obvious. This added layer does not replace security measures, but it reduces exposure. In practice, it is a simple choice that delivers long-term benefits.
How kz43x9nnjm65 Fits Into Modern Systems
The identifier kz43x9nnjm65 follows the same principles seen across modern platforms. It represents a unique reference that systems can trust without context. Whether tied to a record, session, or asset, it exists to be unambiguous and stable across time and environments.
In practical use, such identifiers often sit behind the scenes. Users may never see them, yet they drive everything from retrieval to analytics. When something loads correctly or syncs across devices, an identifier like this usually played a role. Its invisibility is part of its success.
From experience, issues arise when identifiers are reused or altered. Systems lose their sense of continuity. By treating kz43x9nnjm65 as immutable, developers preserve data integrity. This discipline saves countless hours of debugging and prevents subtle, long-term corruption.
Practical Use Cases Across Industries
Identifiers are not limited to one field. In software development, they track users, files, and processes. In e-commerce, they connect orders, payments, and shipments without confusion. Each industry relies on the same core idea: one reference, one truth.
In content systems, identifiers separate presentation from storage. A page title can change while the underlying reference stays fixed. This allows updates without breaking links or analytics. Over time, this separation becomes essential for maintaining large libraries of information.
Even outside pure technology, identifiers appear in logistics and research. Tracking samples, assets, or equipment depends on reliable labels. When scale increases, manual naming fails quickly. Unique strings step in as quiet enablers of accuracy and accountability.
Common Misunderstandings About Identifier Complexity
Many people assume complex identifiers are overengineering. This view often comes from small-scale thinking. In limited systems, simple names work fine. Problems emerge only after growth, integration, or long-term use exposes hidden weaknesses.
Another misconception is that complexity makes systems harder to manage. In reality, the opposite is often true. Clear rules about identifiers reduce decision-making and exceptions. Everyone knows the reference is fixed, which simplifies collaboration across teams.
There is also fear around readability. While humans prefer readable labels, machines do not. The solution is layering. Use friendly names for display and strict identifiers underneath. This balance satisfies both usability and system integrity without compromise.
Long-Term Benefits of Consistent Identifier Design
Consistency pays dividends over time. Systems built with strong identifier practices age better. They accept new features, integrations, and migrations with fewer surprises. This resilience often separates sustainable platforms from fragile ones.
From maintenance experience, identifier consistency reduces technical debt. When references are predictable, refactoring becomes safer. Developers can change structures without losing data relationships. This freedom encourages improvement rather than fear of breaking legacy behavior.
There is also organizational value. Clear identifier policies become shared knowledge. New team members learn faster, and documentation stays simpler. Over years, this clarity compounds, saving effort that would otherwise be spent untangling past decisions.
Human Impact Behind Invisible Systems
Although identifiers feel abstract, they affect real people. When systems fail, users experience frustration, delays, or lost trust. Many of these failures trace back to poor data references rather than visible features. Strong identifiers quietly protect user experience.
In support scenarios, reliable identifiers speed up resolution. Teams can trace issues precisely without ambiguity. This accuracy reduces back-and-forth and shortens downtime. Users may never know why support felt smooth, but the foundation matters.
There is also peace of mind for creators and operators. Knowing that data is anchored to stable references reduces anxiety during updates. Confidence grows when systems behave predictably, even as they evolve and expand.
Conclusion
The identifier kz43x9nnjm65 may look insignificant, yet it reflects a deeper discipline in system design. Unique, stable references keep data accurate, secure, and scalable across time. They reduce errors, support growth, and protect user experience without drawing attention to themselves. Understanding kz43x9nnjm65 is really about appreciating the invisible structures that make modern digital life reliable and resilient.
Read More: Lumerink.com
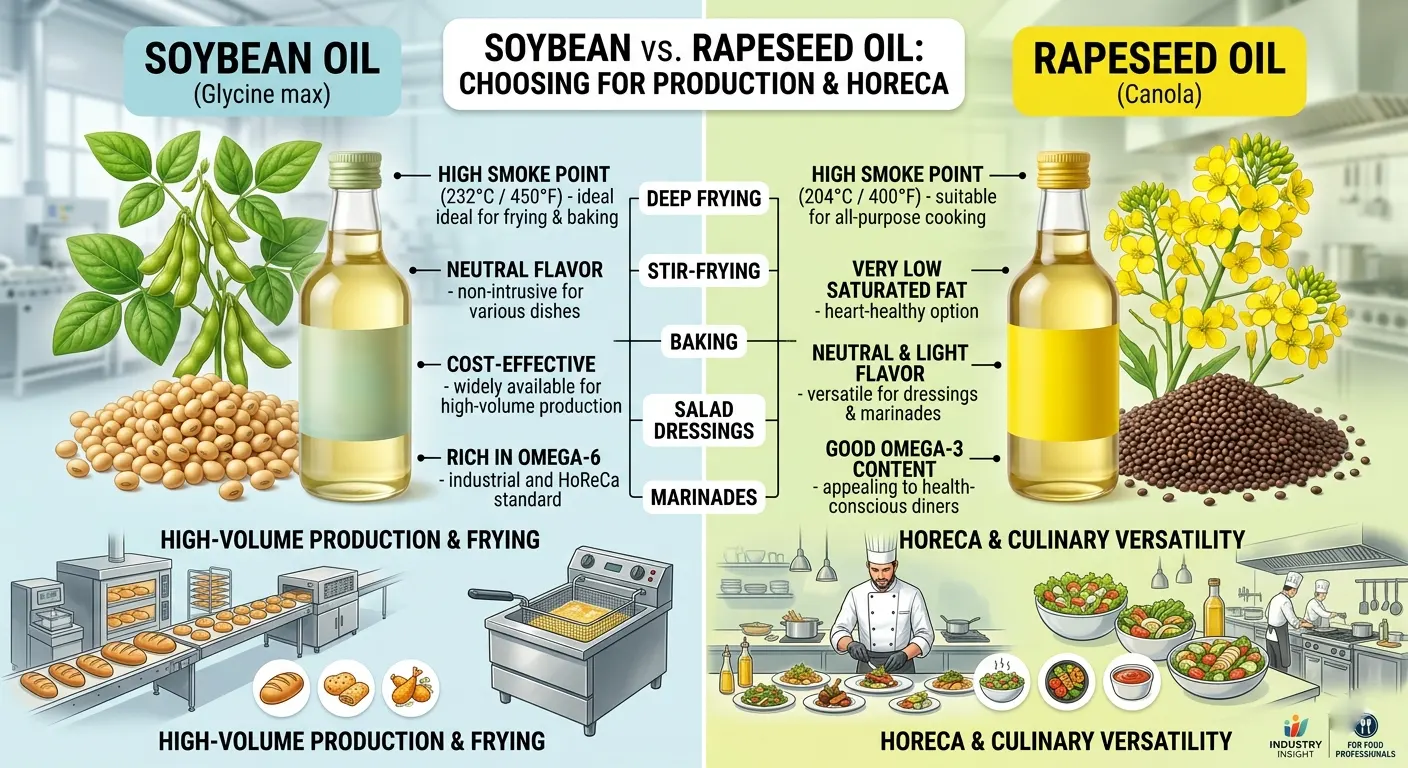
For food producers, restaurants, hotels and catering operators, oil is not just a basic commodity. It influences frying life, shelf stability, taste, nutritional positioning, labeling, waste and final food cost. Soybean oil and rapeseed oil are both neutral vegetable oils, but they are not identical in performance. The right choice depends on the process: cold sauces, baking, ready meals, shallow frying and intensive deep frying all place different demands on fat.
First, terminology matters. Food-grade rapeseed oil is usually low-erucic rapeseed oil, widely known as canola oil in international trade. Codex identifies rapeseed oil as oil from Brassica species and separately defines low-erucic rapeseed oil, including canola oil, as oil from low-erucic varieties. Soybean oil is derived from soya beans, Glycine max. This distinction is important for specifications, labeling and export documentation.
Soybean oil is usually valued for availability, competitive pricing and a clean, neutral flavor. In production it works well in mayonnaise, sauces, dressings, marinades, ready meals, bakery items and snack formulations where the oil should not dominate the recipe. It is convenient for large batches because global supply chains are mature and bulk procurement is often easier than with more specialized oils. For manufacturers working under strict cost targets, standard refined soybean oil can be a rational choice.
Its main limitation is oxidation stability. Conventional soybean oil has a high share of polyunsaturated fatty acids, especially linoleic acid. These fatty acids are nutritionally useful, but they are more sensitive to oxygen, light and heat. In practice, this can mean faster development of rancid notes, darker oil, foaming, sticky fryer residues and shorter frying life. For cold sauces or products with fast turnover, this may be acceptable. For long shelf-life snacks, transparent packaging or continuous frying, it becomes a serious technical factor.
Rapeseed oil has a different strength. It is generally richer in monounsaturated fat, especially oleic acid, and lower in saturated fat than many common edible oils. This gives it a strong nutritional image and typically better heat behavior than oils dominated by polyunsaturated fats. In HoReCa, refined rapeseed oil is popular because it is mild, light in color and flexible. It can be used for sautéing, roasting, baking, dressings, marinades, mayonnaise-style sauces and many frying tasks without changing the flavor profile of the dish.
For frying, businesses should not rely on smoke point alone. Smoke point depends on refining quality, free fatty acids, water, food residues, filtration habits and how long the oil has already been used. A more useful criterion is real oxidative and thermal stability: how slowly the oil forms off-flavors, foam, dark color and total polar compounds during service. Since oleic acid is more stable than linoleic and linolenic acids, high-oleic oils are especially attractive for heavy frying. This applies to both categories: high-oleic soybean oil performs better than conventional soybean oil, and high-oleic rapeseed oil improves durability compared with standard rapeseed oil.
In HoReCa, rapeseed oil is often the safer default when one oil must cover many tasks. It is suitable for restaurants and catering operations that need neutral taste, good menu flexibility and a healthier “house oil” story. It is especially useful for salads, vegetable roasting, pan frying, sauces, bakery glazes and general kitchen use. If the kitchen runs fryers for many hours a day, the best option is refined high-oleic rapeseed oil or a dedicated frying blend rather than ordinary multipurpose oil.
Soybean oil can still be the better option in industrial production. When the oil is used in controlled conditions, protected from oxygen, supported by antioxidants, packed correctly or consumed quickly, it can deliver excellent cost efficiency. It is also practical where the local market is familiar with soybean oil and allergen labeling is not a commercial barrier. For price-sensitive sauces, fillings, ready meals and bakery products, soybean oil can reduce ingredient cost without compromising taste, provided the process does not expose it to excessive heat stress.
Nutrition and marketing also matter. Rapeseed oil is easier to position as a “better-fat” choice because of its low saturated fat and higher monounsaturated fat content. It also contains plant omega-3 in the form of alpha-linolenic acid. Soybean oil also provides essential fatty acids, including linoleic acid and some alpha-linolenic acid, but its higher omega-6 profile may require more careful communication in wellness-focused product lines. For premium HoReCa concepts or retail products with a health-oriented message, rapeseed oil usually fits the brand story more naturally.
Taste is rarely decisive when both oils are refined, because both are broadly neutral. However, cold-pressed rapeseed oil is a separate product: it can have a nutty, seed-like flavor and deeper color. That can be attractive in salads, dips and artisanal bakery products, but it is not a universal substitute for refined oil. In professional purchasing, the specification should clearly state whether the oil is refined, cold-pressed, deodorized, high-oleic, non-GMO, low-erucic or designed for frying.
The practical recommendation is straightforward. Choose refined rapeseed oil when you need one versatile oil for HoReCa, better nutritional positioning, balanced heat performance and neutral flavor. Choose conventional soybean oil when cost, availability and bulk formulation efficiency are the main priorities, especially in cold or moderate-heat production. Choose high-oleic soybean or high-oleic rapeseed when frying life, shelf stability and clean flavor over time are critical. For fryers, always test the oil in the real process: same equipment, temperature, product load, filtration routine and replacement schedule.
In conclusion, there is no universal winner. Rapeseed oil is usually the stronger all-round choice for restaurants, hotels and catering because it combines versatility, neutral taste and a stronger nutrition story. Soybean oil is often the economical industrial ingredient, especially in high-volume recipes where heat stress is limited. For intensive frying and long shelf-life production, the real winner is the high-oleic version or a professionally designed frying blend. The best decision should be based not only on price per liter, but on cost per finished portion, oil turnover, waste, flavor stability, labeling requirements and the promise your brand makes to customers.

TLDR: The digital nomad community has moved well beyond the obvious American cities. In 2026, the most sought-after US bases for remote workers combine affordable living costs, fast internet infrastructure, strong co-working culture, genuine lifestyle appeal, and easy domestic travel connections. This blog covers seven cities that are drawing the highest concentration of location-independent professionals right now and what makes each one worth serious consideration for a long-stay base.
Choosing a base city in the United States as a digital nomad involves a completely different set of criteria than choosing a holiday destination. The questions shift from which landmarks to visit to whether the neighbourhood has reliable gigabit internet, whether the co-working scene has a genuine community or just empty desks, whether the cost of a short-term furnished apartment makes the monthly budget work, and whether the city has enough variety to sustain engagement over a stay of one to three months or longer.
For international digital nomads building their itinerary around extended stays in specific cities, exploring the full range of us travel destinations before committing to a base gives context for how each city fits into a broader American travel experience. Mobimatter supports nomads across every one of these cities with flexible eSim data plans that activate before departure and provide reliable local network connectivity from the moment of arrival, without the cost or complexity of home carrier roaming charges.
1. Austin, Texas: The Nomad Capital of the American South
Austin has established itself as one of the most nomad-friendly cities in the United States over the past several years. Its combination of no state income tax in Texas, a thriving tech and startup ecosystem, warm weather across most of the year, a world-class live music scene, and a genuinely welcoming culture for transplants and remote workers makes it a consistently top-rated base.
The city’s co-working infrastructure is among the strongest outside San Francisco and New York. Spaces like WeWork locations across downtown, Capital Factory for those with startup interests, and dozens of independent neighbourhood co-working spots in areas like South Congress and East Austin give nomads a real choice of working environment to match their daily mood and project type. Short-term furnished apartments are widely available through platforms that cater specifically to the extended-stay market, and the city’s layout makes it easy to cycle or scooter between neighbourhoods rather than relying on a car for every trip.
The food scene, which has evolved dramatically over the past decade, now offers everything from legendary Texas barbecue to outstanding Vietnamese, Mexican, Japanese, and plant-based dining within walking distance of most central neighbourhoods. For nomads who make food culture part of their destination criteria, Austin delivers without requiring a special excursion.
2. Medellín of the North: Why Pittsburgh, Pennsylvania Is Surprising Everyone
Pittsburgh has undergone one of the most dramatic urban transformations of any American city over the past two decades and has emerged as a genuinely compelling digital nomad base that almost no one outside the United States has on their radar. The combination of extremely affordable living costs, a major research university presence, excellent internet infrastructure, and a growing creative community makes it a hidden gem.
The city’s cost structure is dramatically lower than coastal American cities. A furnished one-bedroom apartment in a desirable neighbourhood like Lawrenceville, Shadyside, or the South Side can be found at monthly rates that represent a fraction of equivalent accommodation in New York, San Francisco, or even Austin. This cost advantage allows nomads with standard remote work incomes to live at a quality level in Pittsburgh that would require a substantially higher budget in better-known cities.
The technology sector in Pittsburgh has grown significantly, anchored by Carnegie Mellon University’s robotics and computer science programmes and the presence of major technology company offices including Google, Apple, and Uber. This creates a community of technically skilled, internationally minded professionals that gives the city an intellectual energy that surprises first-time visitors expecting a faded industrial city rather than the genuinely vibrant urban environment Pittsburgh has become.
3. Tucson, Arizona: Desert Living With Mountain Access and Year-Round Sun
Tucson sits in the Sonoran Desert of Southern Arizona and has emerged as a compelling nomad base for those who find Sedona too expensive and Phoenix too spread out. Its combination of affordable housing, outstanding natural access, strong university culture from the University of Arizona, and reliable sunshine across most of the year creates a lifestyle that converts short-term visitors into long-stay residents repeatedly.
The outdoor access from Tucson is genuinely exceptional. Mount Lemmon, which rises to nearly 9,000 feet directly from the city’s edge, offers hiking, skiing in winter, and dramatically cooler temperatures than the desert floor during summer months. Saguaro National Park borders the city on both its east and west sides, putting one of the most iconic American desert landscapes within a fifteen-minute drive of any central neighbourhood.
For best places to visit in usa for first time, Tucson often appears as a day trip destination from Phoenix or a stop on a Southwest road trip rather than a standalone destination. But nomads who spend a month or more here consistently report that its combination of pace, natural beauty, affordability, and creative community makes it far more liveable as a base than the cities people use as jumping-off points to visit it.
The 4th Street arts district and downtown area have developed a genuine independent restaurant, bar, and gallery scene that provides the lifestyle texture that remote workers look for when they are spending weeks rather than days in a city.
4. Chattanooga, Tennessee: The Gigabit City That Remote Workers Keep Discovering
Chattanooga has had a municipally owned gigabit fibre network since 2010, making it one of the fastest-connected cities in the United States at a fraction of the cost charged by private internet providers in major markets. For digital nomads whose work depends on upload speed, video call quality, and consistent connection reliability, this infrastructure advantage is genuinely significant.
The city sits along the Tennessee River at the edge of the Appalachian Mountains, giving it a natural setting that makes it visually distinctive among American mid-sized cities. Rock City, Ruby Falls, and the surrounding trail network provide outdoor access that larger Tennessee cities like Nashville and Memphis cannot match from their urban centres. The revitalised downtown, anchored by the Tennessee Aquarium and a pedestrian-friendly riverfront, gives the city a walkable core that sustains daily life without a car for those who base themselves centrally.
Co-working options have grown alongside the nomad community that the gigabit infrastructure initially attracted. Spaces in the Southside neighbourhood and downtown core serve a community that skews toward developers, designers, and tech-adjacent professionals who specifically chose Chattanooga for its connectivity credentials and stayed for the lifestyle.
5. Minneapolis, Minnesota: The Underrated Cosmopolitan Base for Summer Nomads
Minneapolis is consistently overlooked by international nomads despite being one of the most culturally rich, walkable, and economically vibrant mid-sized cities in the United States. Its summer months from May through September deliver genuinely excellent weather, world-class arts and music programming, outstanding restaurant diversity, and a cycling infrastructure that rivals Amsterdam for an American city.
The Minneapolis and Saint Paul metro area has the largest Somali, Hmong, and Liberian diaspora communities in the United States, which translates into extraordinary food diversity and genuine cultural depth that most American mid-sized cities cannot offer. The restaurant scene in neighbourhoods like Eat Street, Northeast Minneapolis, and the Midtown Global Market delivers food experiences that surprise visitors expecting a bland Midwestern dining culture.
The city’s famous skyway system, an enclosed elevated walkway network connecting 80 city blocks, means that even in transitional shoulder seasons, getting between co-working spaces, restaurants, and accommodation without going outside is entirely practical. For nomads who time their Minneapolis stay for the summer months, the city consistently ranks among the most enjoyable urban bases in the country.
6. Boise, Idaho: The Fastest-Growing Nomad Hub in the Mountain West
Boise has seen dramatic growth in its remote worker population since the pandemic period and has developed the infrastructure and community to support a significant nomad presence without losing the outdoor access and relatively low cost structure that made it attractive in the first place. Its combination of mountain access, genuine affordability, and a surprisingly developed food and arts scene makes it one of the most compelling bases in the Mountain West.
The Boise River Greenbelt, a 25-mile paved pathway running along the river through the heart of the city, gives nomads daily access to outdoor movement without a car or a special excursion. The Boise foothills immediately north of the city offer trail running, mountain biking, and hiking accessible within minutes of downtown. Sun Valley, one of the premier ski and outdoor destinations in the American West, sits within a three-hour drive, making Boise a practical base for nomads who want mountain resort access without mountain resort prices.
The downtown and Hyde Park neighbourhood restaurant scenes have developed genuine quality over the past several years, with independent operators rather than chains defining the character of the dining landscape. The Basque community in Boise, historically significant and culturally active, adds a dimension of genuine cultural distinctiveness that sets the city apart from other Western American cities of similar size.
7. Savannah, Georgia: History, Architecture, and Year-Round Warmth for the Long-Stay Nomad
Savannah is primarily known as a historic tourism destination, but its combination of walkable neighbourhoods, year-round warm weather, significantly lower cost of living than Atlanta, and a genuine arts and culinary scene built around the Savannah College of Art and Design makes it an increasingly attractive long-stay base for nomads who prioritise aesthetics and lifestyle alongside connectivity.
The city’s 22 historic squares create a neighbourhood structure that makes daily life feel genuinely pleasant in a way that grid-pattern American cities rarely achieve. Walking between a co-working space, a lunch spot, and an afternoon coffee under Spanish moss-draped oak trees is a daily experience in Savannah rather than a curated tourist activity. The River Street waterfront provides evening entertainment and dining without requiring transport.
The SCAD presence gives the city a consistent injection of creative energy that keeps its restaurant, gallery, and retail landscape more dynamic than a city of its size would typically sustain. Short-term accommodation options in the historic district give nomads access to antebellum architecture and walkable neighbourhood life that feels completely different from any other American base city on this list.
Staying Connected Across All Seven Nomad Base Cities
All seven cities on this list have reliable 4G LTE coverage and expanding 5G availability in their urban cores, though coverage quality varies in the outdoor and rural areas that make cities like Boise, Chattanooga, and Tucson particularly appealing for nomads who combine remote work with trail access. International digital nomads arriving in the United States for an extended base period benefit significantly from having data active before landing rather than navigating airport connectivity challenges on arrival day. Getting an eSim USA plan from Mobimatter before departure means the first day in any American city is spent exploring and settling in rather than solving connectivity problems. Mobimatter offers flexible US eSim plans across multiple data allowances and validity periods, making it straightforward to match the plan to the actual stay length whether that is three weeks in Austin or three months split between Chattanooga and Boise.
Frequently Asked Questions
What makes a US city good for digital nomads compared to a standard tourist destination?
Digital nomad bases need reliable high-speed internet, a variety of co-working options, short-term furnished accommodation at reasonable prices, a walkable or transit-accessible layout, and enough lifestyle variety to sustain engagement over weeks or months. Tourist destinations optimise for visitor attractions over these practical daily-life requirements, which is why many popular US tourist cities rank poorly as nomad bases despite being excellent to visit briefly.
How do international digital nomads legally spend extended periods in the United States?
Citizens of Visa Waiver Program countries can visit the United States for up to 90 days per entry under ESTA authorization. There is no specific digital nomad visa for the United States currently, meaning international nomads typically work within the 90-day tourist entry allowance. Anyone planning an extended stay should verify current entry requirements and consult immigration guidance relevant to their specific nationality before traveling.
Which of these cities has the best internet infrastructure for remote work?
Chattanooga has a unique advantage with its municipally owned gigabit fibre network that provides consistently fast speeds at lower costs than private internet providers in most American cities. Austin and Pittsburgh also have strong internet infrastructure driven by their technology sector presence. All seven cities have adequate connectivity for standard remote work including video conferencing, cloud file access, and regular uploads.
Is a car necessary for living in these cities as a digital nomad?
It depends on the city and the preferred neighbourhood. Savannah and downtown Pittsburgh are highly walkable. Minneapolis has excellent cycling infrastructure and good public transit. Austin, Tucson, Boise, and Chattanooga are more car-dependent outside their central neighbourhoods, though scooter and bike-share options have improved significantly in all of them. Nomads who choose central accommodation in any of these cities can manage without a car for daily life, though access to the outdoor areas that make several of them appealing typically requires a vehicle or a rental for day trips.
How much does a month of accommodation typically cost in these cities compared to New York or San Francisco?
Furnished short-term apartment costs in these seven cities run significantly lower than coastal gateway cities. Monthly furnished one-bedroom apartments in Pittsburgh and Tucson can be found in the range of $1,200 to $1,800. Austin runs higher at $1,800 to $2,800 depending on neighbourhood. Boise and Chattanooga fall in a similar range to Pittsburgh and Tucson. New York and San Francisco equivalents typically run $3,500 to $6,000 or more for comparable quality, making these mid-sized cities dramatically more cost-effective for extended stays.
Does Mobimatter offer eSim plans suitable for a one to three month stay in the United States?
Yes. Mobimatter offers US eSim plans across a range of validity periods and data allowances designed to accommodate both short visits and extended stays. Nomads planning a multi-month American base period can purchase plans with larger data allowances appropriate for work-intensive usage and select validity periods that match their planned stay length. Multiple plans can be purchased and used sequentially for very long stays.
What is the best time of year to base in each of these cities?
Austin and Tucson are best from October through April to avoid extreme summer heat. Minneapolis and Pittsburgh are most enjoyable from May through September. Savannah is excellent from March through May and September through November. Chattanooga and Boise are strong from April through October. Each city has a genuine off-season that still functions well as a base but requires adjusting expectations around weather and outdoor activity options.

Norway’s approach to wildlife governance is widely regarded as one of the most structured and balanced systems in the world, where ecological sustainability meets public interest. At the center of this framework stands the viltnemnda, a key decision-making body responsible for managing wildlife, preventing conflicts, and ensuring ethical treatment of animals in rural and urban landscapes. Understanding how this institution operates provides valuable insight into Norway’s broader environmental philosophy.
The viltnemnda plays a crucial role in regulating interactions between humans and wildlife, especially in regions where deer, moose, and other wild species frequently intersect with agricultural or residential zones. Its responsibilities extend beyond simple oversight, touching on legal, ecological, and social dimensions of wildlife management. This makes it a cornerstone of sustainable coexistence in Norwegian society.
As environmental pressures and human expansion increase, the importance of structured wildlife governance becomes even more significant. The viltnemnda ensures that decisions are not only legally compliant but also ethically sound and ecologically balanced. This article explores its structure, functions, challenges, and evolving role in modern conservation systems.
Understanding Viltnemnda and Its Role
The viltnemnda is fundamentally a municipal wildlife committee tasked with overseeing local wildlife management policies. It operates under national environmental laws but has localized authority to make decisions tailored to regional ecosystems. This decentralized structure allows flexibility in addressing unique wildlife challenges across Norway’s diverse landscapes.
In practice, the viltnemnda handles matters such as hunting quotas, injury reports involving wildlife, and interventions in human-wildlife conflicts. Its members often include local representatives with knowledge of ecology, agriculture, and public safety. This multidisciplinary composition ensures that decisions reflect both scientific understanding and community needs.
Beyond administrative duties, the viltnemnda also serves as a mediator between environmental agencies and local residents. It plays a vital role in ensuring that wildlife conservation efforts do not conflict with rural livelihoods. By balancing these interests, the committee maintains harmony between nature and society.
Will You Check This Article: The Power of Tracqueur Technology in Modern Tracking
Historical Development of Wildlife Management in Norway
The origins of structured wildlife governance in Norway can be traced back to traditional hunting regulations and communal land management practices. Over time, as wildlife populations grew and human settlement expanded, the need for formal institutions like the viltnemnda became evident. Early systems were informal but gradually evolved into legally defined bodies.
During the 20th century, Norway experienced significant environmental reform, leading to the establishment of modern wildlife management frameworks. The viltnemnda emerged as a result of these reforms, designed to decentralize decision-making while maintaining national oversight. This allowed local communities to actively participate in conservation efforts.
Today, the historical evolution of the viltnemnda reflects Norway’s broader commitment to sustainability and democratic governance. It represents a shift from purely extractive wildlife use toward a more balanced ecological approach. This transformation continues to influence how wildlife policies are shaped and implemented.
Legal Framework Governing Viltnemnda
The operations of the viltnemnda are grounded in Norway’s Wildlife Act, which defines the rights and responsibilities associated with wildlife management. This legal structure ensures that all decisions are made within a consistent national framework while allowing local adaptation. It also establishes guidelines for ethical hunting and species protection.
Under this legal system, the viltnemnda has authority to assess wildlife populations and recommend harvesting quotas. These recommendations are based on scientific data, population surveys, and ecological assessments. The goal is to maintain biodiversity while preventing overpopulation or ecological imbalance.
Additionally, the legal framework ensures accountability and transparency in all viltnemnda decisions. Public reporting, environmental audits, and inter-agency collaboration are key components of this governance model. This structured approach helps maintain trust between authorities and the public.
Organizational Structure and Responsibilities
The viltnemnda is typically composed of appointed members who represent different sectors of the community. These may include agricultural stakeholders, environmental experts, and local government officials. This diversity ensures that multiple perspectives are considered in decision-making processes.
One of the primary responsibilities of the viltnemnda is to monitor wildlife populations and assess ecological health within its jurisdiction. This includes tracking species such as moose, deer, and smaller game animals. Data collected is used to guide hunting regulations and conservation measures.
In addition, the viltnemnda is responsible for responding to incidents involving injured wildlife or dangerous animal behavior. It coordinates with emergency services and wildlife experts to ensure humane and effective interventions. This operational role highlights its importance in both ecological and public safety contexts.
Decision-Making Process in Viltnemnda Cases
Decision-making within the viltnemnda follows a structured and evidence-based process. Cases are typically initiated through reports from citizens, environmental agencies, or field observations. Once a case is submitted, it undergoes thorough evaluation based on ecological data and legal guidelines.
The committee then reviews scientific input, including population studies and environmental impact assessments. This ensures that every decision made by the viltnemnda is grounded in factual and reliable information. Public input may also be considered, especially in cases involving local community concerns.
Final decisions are made collectively, ensuring that no single member has unilateral authority. This collaborative approach strengthens accountability and reduces bias. It also reflects Norway’s broader commitment to democratic and transparent governance in environmental matters.
Human–Wildlife Conflict and Mitigation Strategies
One of the most significant challenges addressed by the viltnemnda is human–wildlife conflict. As urban areas expand into natural habitats, encounters between humans and wild animals have become more frequent. This includes crop damage, traffic accidents involving animals, and property risks.
The viltnemnda develops mitigation strategies such as controlled hunting, relocation of animals, and installation of warning systems in high-risk areas. These measures are designed to minimize harm while preserving ecological balance. Preventive planning is a key aspect of its strategy.
Education also plays a vital role in reducing conflicts. The viltnemnda often collaborates with local communities to raise awareness about wildlife behavior and safety practices. By promoting coexistence, it reduces the likelihood of dangerous encounters and supports long-term sustainability.
Challenges and Modernization of Viltnemnda
Despite its effectiveness, the viltnemnda faces several modern challenges. Climate change, habitat loss, and increasing urbanization all place pressure on wildlife management systems. These factors require continuous adaptation and policy updates.
Technological advancements are also reshaping how the viltnemnda operates. Digital tracking systems, satellite monitoring, and data analytics are increasingly used to improve decision-making accuracy. However, integrating these tools requires training and resource investment.
Another challenge is maintaining public trust and engagement. As societal values evolve, the viltnemnda must ensure transparency and inclusivity in its operations. Balancing traditional practices with modern environmental science remains an ongoing task.
Conclusion
The viltnemnda stands as a vital institution in Norway’s environmental governance system, bridging the gap between human development and wildlife conservation. Its structured yet flexible approach allows it to address complex ecological challenges while respecting local needs and national regulations.
Through its legal authority, scientific grounding, and community involvement, the viltnemnda ensures that wildlife management remains both ethical and sustainable. Its continued evolution reflects the growing importance of adaptive governance in a changing world.
As environmental challenges intensify globally, the role of the viltnemnda becomes even more significant. It represents a model of balanced coexistence, where nature and society are managed not as opposing forces but as interconnected systems working toward long-term harmony.
Read More: Pointmagazine.co.uk

Top Lululemon Collections Worth Knowing in 2026

Soybean vs rapeseed oil: which one to choose for production and HoReCa

Reputation Recovery: Using Reddit Engagement Strategically

ABS Testauslösung Explained: Safety, Diagnostics & Performance
Otorrent.com Explained: Streaming, Risks, and Safe Use
